Introducing Command R+: Our new, most powerful model in the Command R family.
embed
AI for language understanding
Embed is Cohere’s leading text representation language model. It improves the accuracy of search results, retrieval-augmented generation (RAG), classification, and clustering.
embed
AI for language understanding
Embed is Cohere’s leading text representation language model. It improves the accuracy of search results, retrieval-augmented generation (RAG), classification, and clustering.


embed
AI for language understanding
Embed is Cohere’s leading text representation language model. It improves the accuracy of search results, retrieval-augmented generation (RAG), classification, and clustering.

Leading embedding performance
Robust to noisy data
Noisy data often contains errors, outliers, and irrelevant information that hinder an embedding model’s ability to discern meaningful patterns or relationships within the data. Our Embed model understands your data’s nuances, making it highly accurate even when dealing with noisy real-world datasets.

Better retrievals for RAG
The effectiveness of RAG is dependent on multiple components, including embedding models that power search systems to retrieve relevant information. Embed’s elevated accuracy facilitates highly relevant and fewer search results, saving time and computational resources for retrievals.
What’s possible with Embed

semantic search
Embeddings enable searching by meaning, which leads to search systems that better incorporate context and user intent than previous keyword-matching systems.
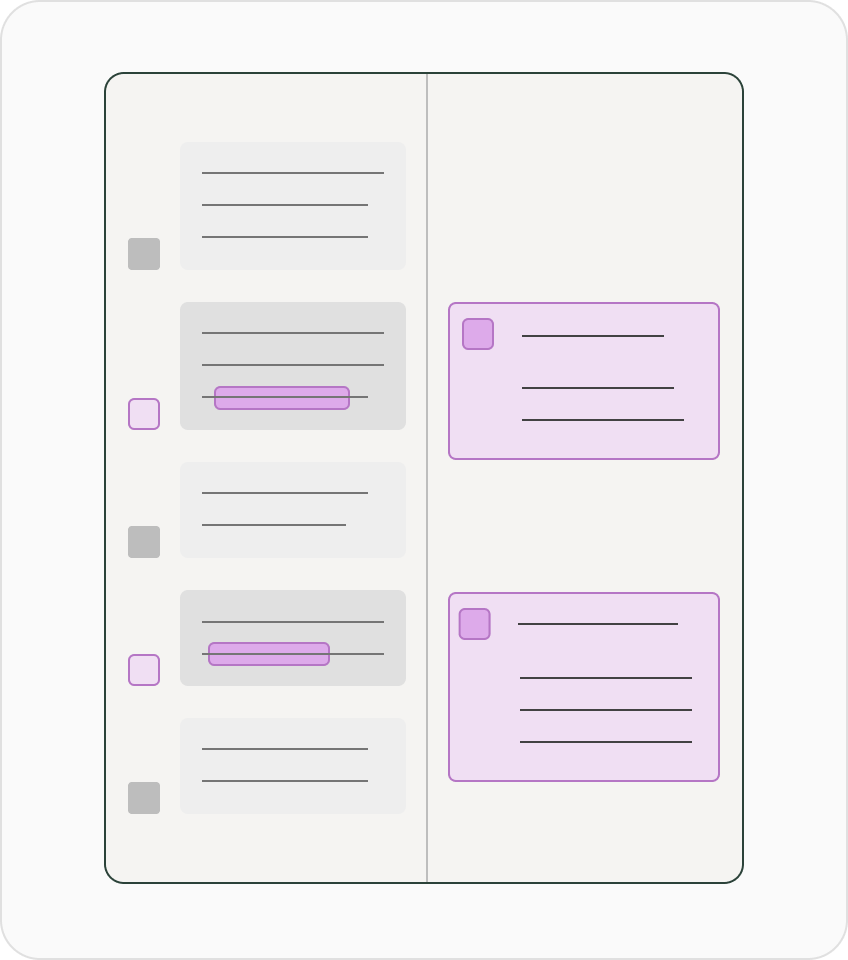
Retrieval-augmented generation
Improve RAG systems by using a performant embedding model especially tuned for search.
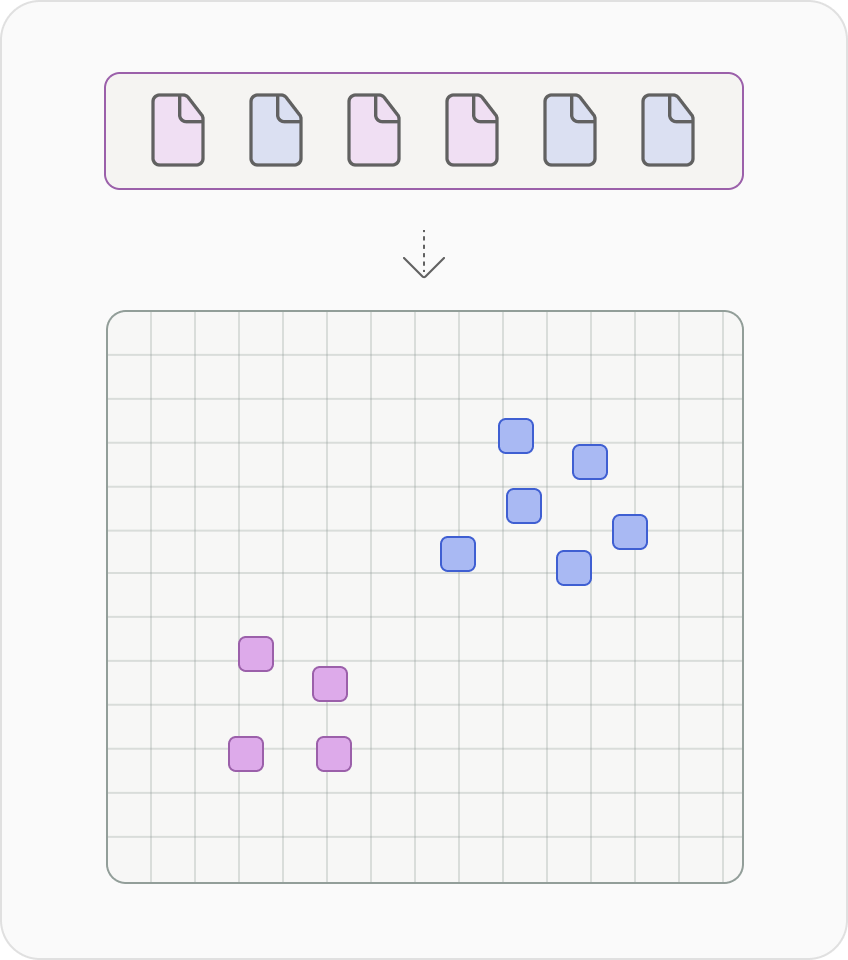
Clustering
Make sense of large text archives by grouping similar texts based on their meaning (as captured by embeddings). Uncover patterns like often commonly asked questions or grouping similar types of issues.
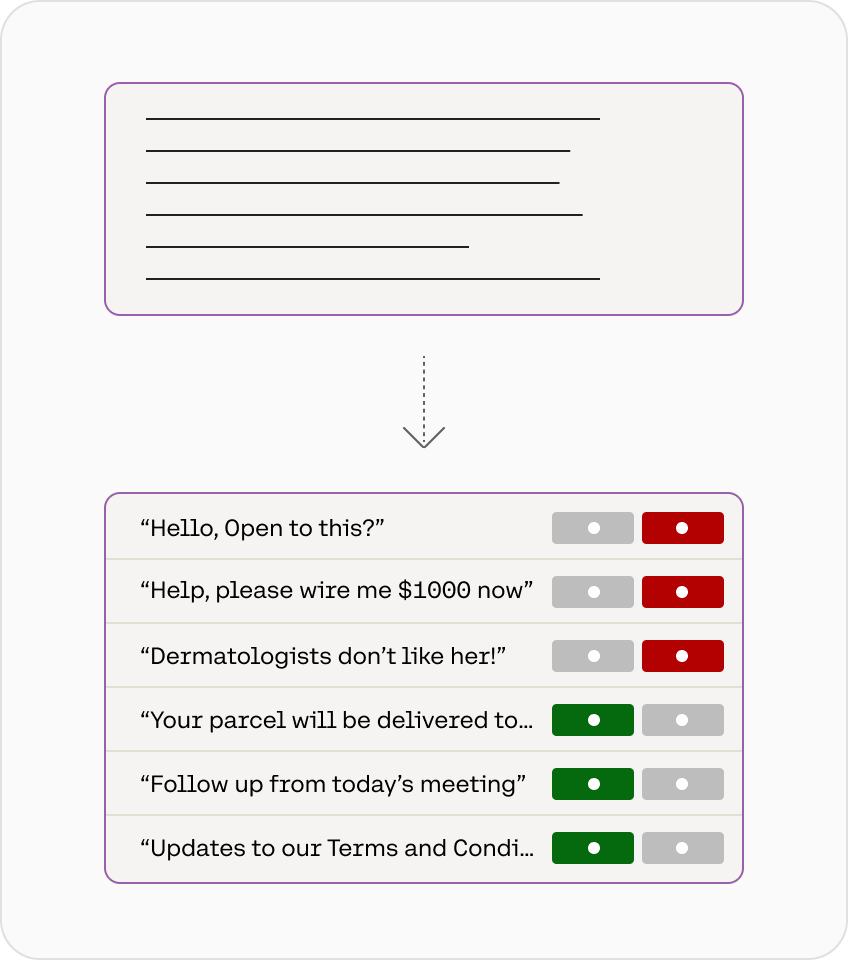
Text classification
Build systems that automatically categorize text and take action based on the type (e.g., route this message to sales, escalate that other message to tier 2 support).
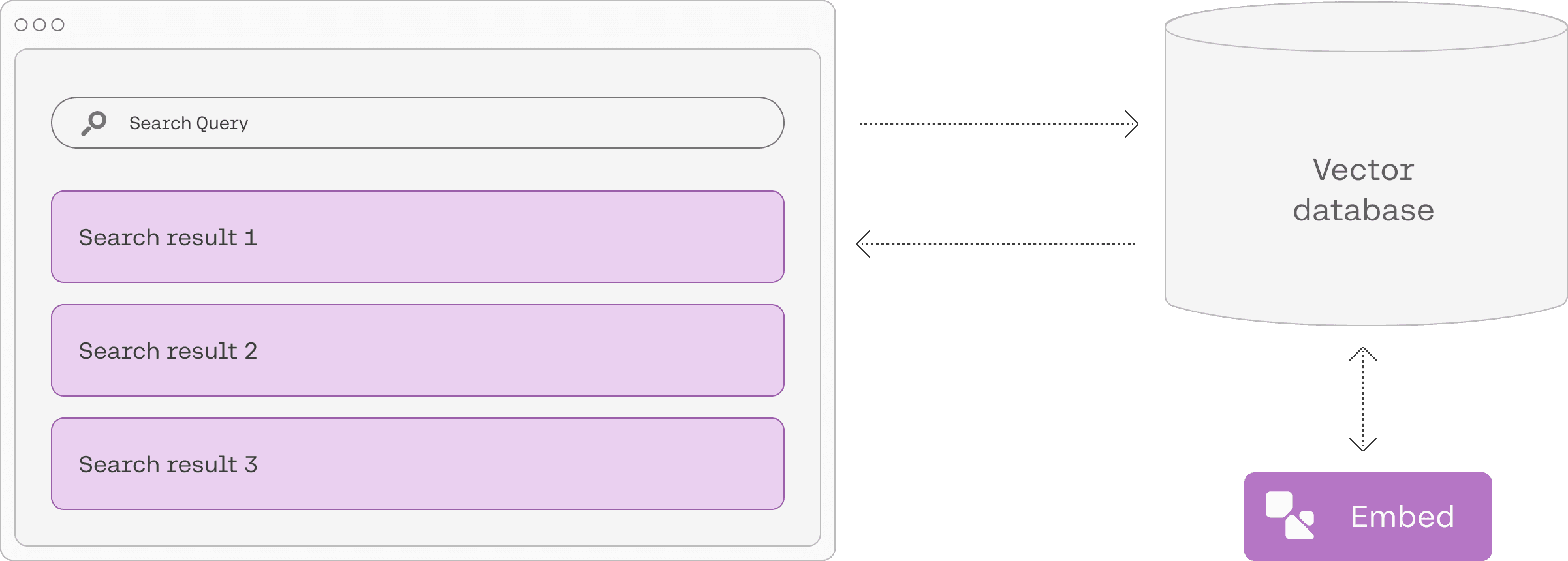
Language Models Optimized for Semantic Search
Use Embed with a wide variety of vector databases that directly integrate with the Embed model.
“From our experience, Cohere’s support is #1, and the embeddings endpoint has given us excellent results, outperforming other models”
— Co-founder, CEO

Embed resources


Ready to get started?
Create an account and build with Cohere